Neue Hardware – neue Möglichkeiten
Seit kurzem steht mir ein aktueller (Mitte 2025) PC mit einem AMD Ryzen 9950 X3D Mikroprozessor und einer Nvidia RTX 5090 Grafikkarte zur Verfügung. Das ist eine echt krasse Kombination von Hardware und die Grafikkarte speziell dazu gemacht, jedes aktuelle Spiel, auch die mit 4K, mühelos laufen zu lassen. Ich habe 2 Spiele, Fortnite und Red Dead Redemption 2, die auch schon mit meiner alten RTX 2080 Super problemlos – aber bestimmt mit weniger Special Effects – mit 4K liefen, ausprobiert und erwartungsgemäß hatte die Monstermaschine keine Probleme damit.
Nicht fürs Zocken geholt
Aber ich habe sie mir nicht zum Spielen geholt! Es gibt nämlich noch eine andere Anwendung, die mit so einem Number-Cruncher angegangen werden kann: KI! Schon kurz nach der Vorstellung von ChatGPT 3.5 im November 2022 wurmte mich der Gedanke, dass diese mich total faszinierende KI auf amerikanischen Servern läuft und nicht bei mir zu Hause. Denn mit dem Erscheinen von ChatGPT und gpt-3.5 war etwas bisher Unglaubliches wahr geworden: Eine übermenschliche Intelligenz! Aber sie lebte auf irgendwelchen riesigen Servern in den USA. Nichts, was ich bei mir zu Hause haben, mein persönlicher Assistent, mein Lebensberater oder mein intellektueller Freund sein konnte. Das hört sich jetzt ein bisschen übertrieben an, aber das LLM wirkt bei der textbasierten Kommunikation tatsächlich wie ein Mensch und übertrifft diesen an intellektueller Leistung in den meisten Fällen.
Durch die mit dem LLM einhergehenden Möglichkeiten entwickelte ich schnell eine starke Bindung und wollte es nicht mehr missen. Aber was wäre, wenn die USA das einfach wieder abschaltet? Dass die damit meine Daten frei Haus bekamen, interessierte mich in dem Moment weniger, obwohl das natürlich ein mindestens ebenso großes Problem ist. Gezielt begann ich nach Möglichkeiten zu suchen ein LLM lokal bei mir laufen zu lassen. So entdeckte ich die ersten lokalen KIs:
|
Datum |
Name |
|
Feb 2023 |
Meta veröffentlicht LLaMA 1 (nicht ganz offen, nur für Forschung) |
|
März 2023 |
LLaMA 1 wird geleakt – Community kann es lokal nutzen |
|
März 2023 |
Stanford veröffentlicht Alpaca (fein getuntes LLaMA) |
|
April 2023 |
Vicuna 13B erscheint (von UC Berkeley) |
|
Juli 2023 |
Meta veröffentlicht LLaMA 2 (komplett offen) |
Erste lokale Experimente
Ich habe damals LLaMA 1 (7B quantisiert) und etwas später Vicuna ausprobiert. Dass ich sie überhaupt zu Hause mit der RTX 2080 zum Laufen bekam, war für mich ein Meilenstein in meinem Informatikerleben und machte mir Hoffnung. Doch die ersten Tests waren ernüchternd. Teilweise funktionierte es in deutscher Sprache nicht und wenn, war die Rechtschreibung oder Grammatik nicht brauchbar. Auch der reine Informationsgehalt war nicht gut oder halluziniert. So genau weiß ich es nicht mehr, aber jedenfalls genügte es meinen Vorstellungen nicht.
Mit Vicuna konnte man die Modelle auch auf dem PC-Mikroprozessor, also ohne Grafikkarte oder zusammen mit der Grafikkarte laufen lassen, was schön gezeigt hat, dass die Grafikkarte essentiell ist aber die Modelle noch nicht gut genug. Das führte dazu, dass ich die Experimente wieder einstellte und mich anderen Dingen widmete. So testete ich zum Beispiel die lokale Variante des Bilderzeugungssystems Stable Diffusion mit einem sehr positiven Ergebnis, welches ihr unter Traumshooting mit einem Supermodell nachlesen könnt.
2025 – alles neu mit LM Studio
Jetzt ist es 2 Jahre später und ich war sehr neugierig darauf auszuprobieren was mit der neuen Grafikkarte, ich hatte jetzt immerhin 2 Generationen übersprungen, in Sachen lokale KI möglich ist. Kurz zuvor hatte ich bei der Arbeit mit meinem alten PC das Programm LM Studio entdeckt, mit dem es sehr viel einfacher war lokale Modelle auszuprobieren. Die waren schon besser als die Modelle von vor 2 Jahren.
Also LM Studio auch auf dem neuen PC installiert und nach Modellen gesucht, die so in etwa in meinen neuen Grafikkartenspeicher von 32 GB passen. Gleich nachdem die großen Dateien geladen waren, kann ich sie innerhalb der GUI von LM Studio ausprobieren. Für mich ist es nicht leicht, ein Modell zu beurteilen, aber grundsätzlich antworteten mir die neuen Modelle alle in einwandfreiem Deutsch – was schon eine große Verbesserung zu vor 2 Jahren ist.
Die ersten Antworten auf Fragen waren gut, aber ob sie mit den großen Modellen wie GPT-4o mithalten können, konnte ich nach den ersten Tests nicht sofort beantworten. Mein positiver Eindruck steigerte sich aber schnell, als ich das erste Mal einen englischen Text in das Eingabefeld droppte – und dieser wenige Sekunden später in einwandfreiem Deutsch zu lesen war! Das war eindeutig eine Leistung, die ein durchschnittlicher Mensch so schnell nicht hinbekommt. Und nun kann sogar ein lokales Modell für mich übersetzen! Ich brauche noch nicht einmal Internet dazu! Mit dieser Leistung bewies das lokale Modell seine Daseinsberechtigung.
Ich frage mich schon seit einiger Zeit, ob DeepL überhaupt noch eine Chance gegen die großen KI-Anbieter hat?
Idee: KI-Service für Webseiten
Schon seit längerer Zeit habe ich im Hinterkopf die Idee, eine Serviceleistung für Firmen aufzubauen, die einen intelligenten Berater für die von der Firma angebotenen Dienstleistung erschafft, der dann zum Beispiel als wirklich intelligenter Chat Agent auf der Firmenwebseite integriert ist. Ich weiß, das gibt es schon, aber ich wollte meine eigene Lösung erschaffen. Darum begann ich gleich zu recherchieren, wie ich das jetzt über LM Studio laufende Modell ins Internet bringen kann.
Zum Glück kann man in LM Studio einen eingebauten Webserver aktivieren. Für diesen entwickelte ich zusammen mit ChatGPT und Grok eine PHP-Seite zum Testen. Ihr findet sie hier: Rodensteiner KI. Aber was mit KI und lokaler KI wirklich los ist, das kommt jetzt.
Bildverschlagwortung mit KI
Ich saß also so da und überlegte, was ich noch alles mit 32 GB Videospeicher anstellen konnte – und da fiel mir ein, dass ich in der c’t einmal etwas von der Verschlagwortung von Bildern mit Hilfe von KI gelesen hatte. Ich habe über 200.000 Bilder und es ist schwierig, darin noch gezielt etwas zu finden. Ja, ich hätte sie von Anfang an verschlagworten sollen – habe ich aber halt nicht gemacht. Und wenn ich das jetzt nachholen würde, müsste ich wahrscheinlich den Rest meines Lebens Bilder verschlagworten.
Doch schon als ich im c’t-Artikel die Worte Ollama und Docker las, hatte ich keine Lust mehr das Beispiel der c’t zu realisieren. Um auf meinem neuen Rechner nicht zu viele grundsätzlich ähnliche Systeme zu haben, wollte ich bei LM Studio bleiben, welches mir um so besser gefällt – um so länger ich damit arbeite. Und erst Docker zu installieren, damit ich dann so einen Container einrichten kann, wollte ich auch nicht.
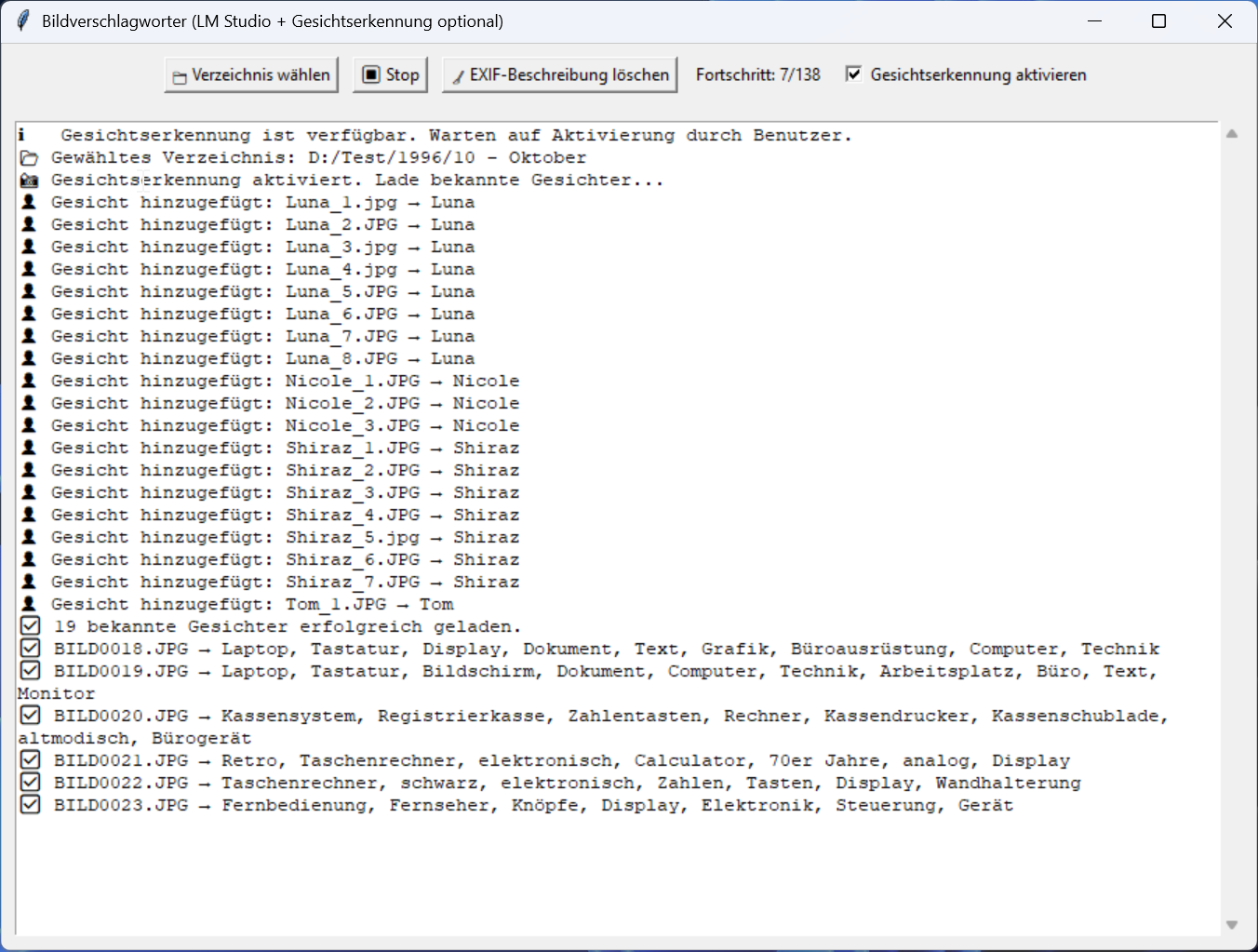
Es war ja doch grundsätzlich nichts weiteres nötig, als den schon gestarteten Webserver von LM Studio. Den Rest kann man einfach mit ein paar Python-Programmen erledigen. So hatte ich wenig später ein Python-Programm, welches rekursiv durch meine Bildersammlung lief, jedes einzelne Bild über den Webserver an mein lokales Modell übergab – und eine Sekunde (!) später die Schlagwörter zurück bekam, die mein Python-Programm in die EXIF-Informationen des Bildes schrieb! Zum Testen habe ich dann erst einmal etwas über 16.000 Bilder einer USA-Reise verschlagworten lassen. Das dauerte etwa 5 Stunden. Und hat mich echt beeindruckt!
Personenerkennung
Ein Familienmitglied machte mich darauf aufmerksam dass ich gar nicht nach den Vornamen unserer Familie suchen kann! Darum habe ich anschließend noch eine Gesichtserkennung integriert. Die arbeitet ohne die Grafikkarte und nutzt für ihre Arbeit den Hauptprozessor. So hat der Ryzen 9950 auch mal was zu tun. Die Einrichtung ist nicht ganz simpel aber zu bewältigen. Allerdings verlangsamte das die Verschlagwortung deutlich und darum habe ich es nur gemacht, wenn die vorher laufende eigentliche Verschlagwortung die Worte Mensch, Mann, Frau, Junge, Mädchen oder Kind beinhalteten. Das beschleunigte den Vorgang wieder deutlich.
Bilddatenbank mit Python & SQLite
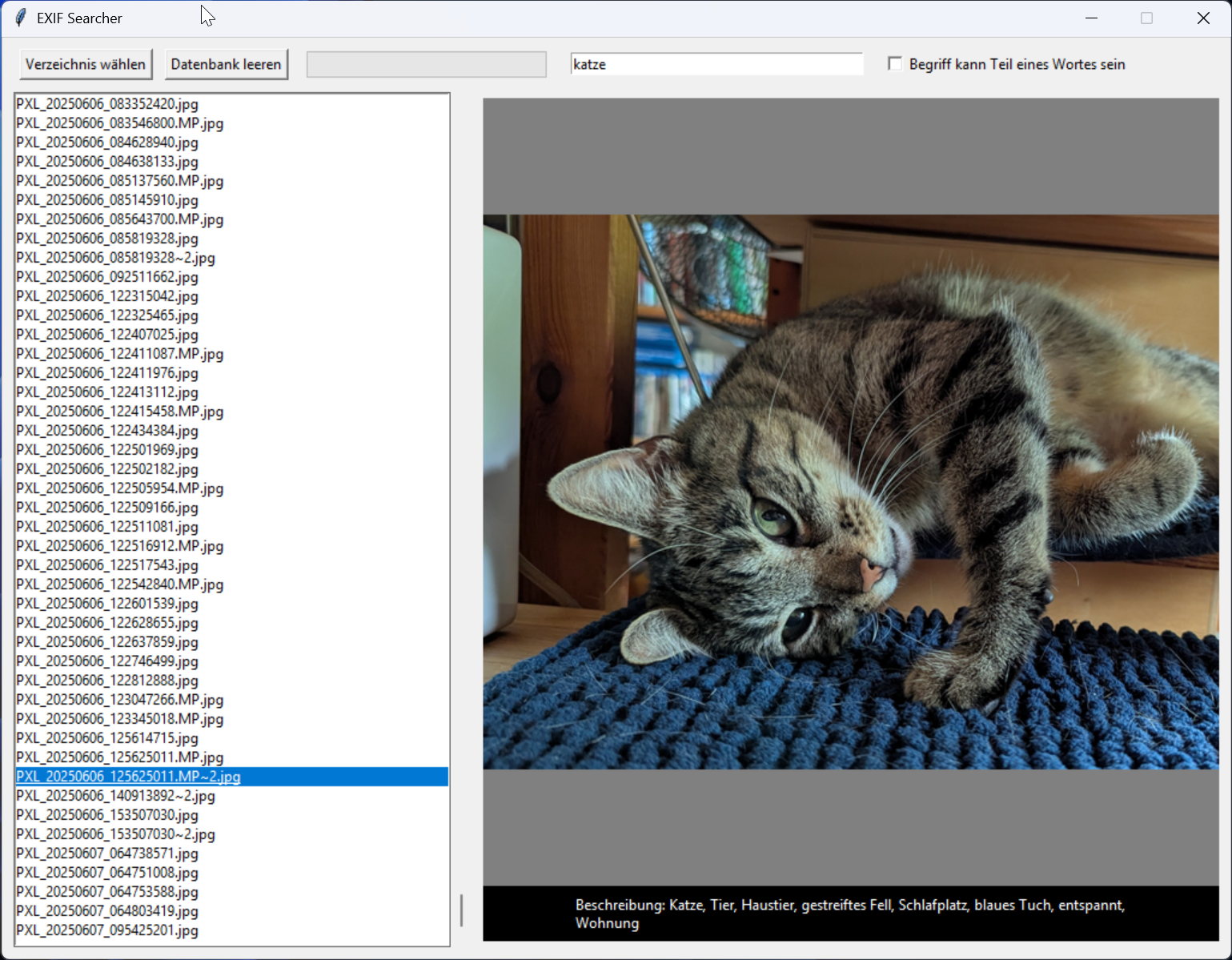
Um nun wirklich etwas von den Schlagwörtern zu haben, habe ich noch schnell ein Python-Programm entwickelt, welches wiederum durch alle Bilder geht, die Schlagwörter heraus liest und in einer SQLite-Datenbank so speichert, dass ich innerhalb von Sekundenbruchteilen alle Bilder finde, die ein oder mehrere Wörter enthalten.
Ich habe also eine Fundstellenliste und wenn ich dort auf ein Bild klicke, wird es direkt neben der Liste gezeigt. Klicke ich auf das Bild, geht mein unter Windows installierter FastStone Image Viewer auf und ich kann die Umgebung des Bildes in vielen kleinen Icons sehen. Also dann meist noch andere Bilder, die mit dem gefundenen Bild in Verbindung stehen.
Ich weiß nicht, ob ihr es nachvollziehen könnt, aber das war eine wirklich krasse Erfahrung für einen langjährigen Informatiker wie mich. Das Zusammenspiel von der RTX 5090, dem lokalen KI-Modell, der Arbeit von mir zusammen mit den externen KIs, um die Python-Programme zu entwickeln, hat mir in weniger als einem Tag eine Lösung gebracht, um endlich sinnvoll mit meinen vielen Bildern umgehen zu können.
KI verändert meine Welt
Mir war Ende 2022 klar, dass gerade etwas wirklich, wirklich Großes passiert. Aber heute bin ich absolut überzeugt, dass KI für mich die Welt verändert hat. Ich bin ein Mensch mit vielen Ideen, aber in der Vergangenheit habe ich nur wenige davon realisiert, da ihre Umsetzung immer sehr viel Zeit kostet. KI macht es mir möglich, nahezu jede Idee sofort umzusetzen.
Dinge, für die ich früher Tage oder Wochen gebraucht hätte, mache ich jetzt in wenigen Stunden. Die Firma mit Programmierern, die alles programmieren, was ich von ihnen will – und die ich immer haben wollte – die brauche ich nicht mehr. Mit Hilfe von KI mache ich das jetzt schneller.
Fazit – warum die RTX 5090 Gold wert ist
Um noch einmal zum Titel zurückzukommen: Mein alter PC war eigentlich noch brauchbar. Mit dem ersten Consumer-16-Kern-Mikroprozessor von AMD, dem Ryzen 3950 X, und der schon erwähnten RTX 2080 Super erledigte er mühelos alle Aufgaben bis zum gehobenen Videoschnitt mit Davinci Resolve. Aber sein Videospeicher von 8 GB war zu klein für die besseren KI-Modelle.
Das ist jetzt mit den 32 GB der RTX 5090 kein Problem mehr. Es ist absolut faszinierend, wie nach einer Anfrage nahezu sofort die Tokens in den Ausgabebereich von LM Studio sprudeln. Oder Bilder mit 5472 × 3648 Pixeln in einer Sekunde getaggt werden!
Ich freue mich auf die Zukunft, in der es wahrscheinlich bald immer leistungsfähigere lokale KI-Modelle geben wird – und auf das Ausprobieren unzähliger Ideen zusammen mit lokaler KI.